Inspired by:
https://g.co/gemini/share/a41a715cdc94
and
https://xkcd.com/980/

Debt. It is in each of our lives and frankly, how we built tomorrow today.
To think there is a way to go through life without ever incurring debt is to live a life that spends more time tending to things personally that could be spent building bigger things – collectively – and then paying those back with the benefits of what you built together along with the satisfaction of helping someone that helped you.
We put off or defer things today to build improvements we wish in our lives, but when it comes time to pay the bill, we begrudgingly wish to pay the bill. Is it entitlement? Is it just the idea of trying to cheat reality to get something for nothing? Physics teaches us in the laws of energy conservation that we cannot get motion without an energy expense. Why would economics be any different?
There are other cases as well where both technical debt and Brooks’s law likely contributed to the projects overall failure:

The Space Shuttle project was doomed almost from the beginning in design and goals. NASA originally wanted a purely liquid fueled space craft capable of reuse. After the Apollo missions were shutdown, there was a drastic change in the country’s funding priorities and ultimately both the DOD and NASA were forced to work together. There is some debate whether or not philosophical design differences lead to the decision of solid rocket boosters mostly used by DOD in the nuclear ICBM arsenal played a factor in them being incorporated into the Space Shuttle design but it is most apparent that cost cutting incurred more technical debt which never was fully repaid over the programs history leading to tragic losses of life.
https://en.wikipedia.org/wiki/Space_Shuttle_design_process
“The wrong car at the wrong time.”
“The aim was correct, but the target had moved.”
The Ford Edsel was plagued by compromised decisions in design, management decisions that were to “streamline” the models across various makes. These changes caused the production line to suffer overall as there wasn’t a dedicated Edsel production line causing existing production lines to have to retool and re-bin parts every time Edsel were produced in the existing factories. The end result was a product nobody wanted due to lack of a real feedback loop from the customer to the designers and management.
https://en.wikipedia.org/wiki/Edsel#Edsel’s_failure

The Panama Canal Development was the plan to join 51 miles of waterways to connect the Atlantic ocean to the Pacific. Actual planning began over 150 years prior to the actual opening of the canal that occurred within a 10 year project span. This comparatively short time span (which was in fact ahead of schedule by two years) was assisted with a prior French effort happening from 1881-1899 that ended in dismal failure due to disease and brutal underestimation of the needed efforts.
https://en.wikipedia.org/wiki/Panama_Canal#French_construction_attempts,_1881%E2%80%931899
Brooks also discusses several other concepts and challenges in software development, including:
Conceptual Integrity: The importance of maintaining a consistent design and architecture throughout the development process to ensure the overall quality and coherence of the final product.
The Tar Pit: The complexity of software development, likened to a tar pit where projects can easily become mired in difficulties and delays.
Surgical Team Model: The idea that small, skilled teams are often more effective than larger, less cohesive ones, particularly in complex projects.
The Second-System Effect: The tendency for engineers to overdesign their second system, leading to unnecessary complexity and delays.
No Silver Bullet: Brooks argues that there is no single, revolutionary innovation or approach that can magically solve all the inherent difficulties and complexities of software development.
But technical debt is a silent killer of projects and budgets. It leads to increased effort and cost on work already “completed”. Probably one of the biggest examples is the “Year 2000” problem where data storage allocations only accounted for 100 years, from 1900 to 1999 and not 1000 or 10000 years. Considering modern computing only became common place for maybe 50 of those years, this is an incredible oversight.

Even to this day, there are systems in operation built and still operating from this era that obviously went through this “technical debt” maintenance operation that have not changed and are still operated as critical operations for many major corporations and government entities.
Migration to more modern hardware and virtual platforms is only a partial solution as the reason these systems existed for so long is due to having deep assessment and accounting of their operations over a long period of time.
Any architectural change to this platform has the potential of introducing unexpected changes to the application being supported. And as many of these systems are financial in nature, could directly cost the organization who runs them substantial costs. These applications are crucial across many different industries. From accounting of medical costs to insurance or Medicare, to payroll and unemployment benefits to a state’s rolls, and many in between from aerospace to agriculture.
In the end, these are systems which will take a long time and big budget to properly engineer and develop systems to eventually replace them. A shortcut solution will not be applicable here without extensive testing and signoff.
Don’t forget there is a datetime issue coming in 2038 relating to 32bit addressing. So tick-tock…
Obligatory XKCD on the topic…
Today, data now lives in “clouds”. Well, not in fluffy transitional forms of water vapor but in large amorphous buildings known as datacenters. We like to joke that companies did not move their computing resources to a cloud, but to someone else’s datacenter.

But it took more than that to get here. The first is to transition from servers that were built and cared for as a singular project to something that scales. We call this mindset as treating them as “pets” and often engineers would treat them like pets, going as far as giving them individual names. The problem with this mindset is that we then begin caring for them as such. This includes patching and systems maintenance. Projects built on them would also become myopic in their scope in that applications would then be built around this “family” infrastructure which then become inevitable thinking of continual improvement – while not bad in and of itself – made the whole application being run in this “pack” of server hardware, a one-off.

Duplicating a one-off can be difficult in systems engineering parlance. While installing the operating system and base system components usually is fairly set, where it become unique is the software configuration for the application, the network and storage requirements, cabling and hardware resources for it to scale horizontally to compensate for when computing resources push the hardware to its vertical limits of the platform.
The biggest problem: getting it exact every time you add a new server or propagating changes across multiple “duplicate” hosts.

This is the point where we began to treat systems and the entire infrastructure as software code (Infrastructure as Code – IaC). The premise here is that there would be a single source of “truth” which is usually the scripting and software used to manage the servers and they would interrogate the servers as to their “state” information – including patching, software configuration, right down to their kernel and network configurations.
The effect of which is that we can now completely wipe out a complete server or replace it and rebuilt it to be configured exactly the way we wish it to become at the press of a button.
Servers are no longer “pets” at this point.
They become what we call “cattle” and lends to the idea of “idempotence” where a server becomes the result of software code instructions and not the culmination of continual tuning and maintenance on individual systems.
Improvements are made in software versions, iterated instructions and propagated through management software to all applicable servers in machine coded fashion.
Deus ex machina.
Now that we have scriptable software installing the operating system and the applications to be run on them (along with their configuration components), we now turn our attention to increasing our computing density.
When the Apache web server was released, it eventually offered a feature that is part of the HTTP exchange representing that the request is asking for xyz web server. This is partly for SSL and HTTPS reasons, but more importantly its because a single webserver can host multiple websites on a single server and part of the HTTP exchange is reporting this to the Apache webserver which in turn goes to the correct configuration in its software and serves out the correct set of files from its storage back to the requesting client.

But this is just for webservers – how can you do the same for whole computers where you may have some servers that get traffic occasionally and others who may have loads of traffic. Both cost relatively the same, both use the same resources and energy. But, can you take advantage of the unused resources of hosts to serve out more applications? More to the point, can you make a machine within a machine?
At this point we are beginning to get closer to the “Second-System” anti-pattern but I will address this in just a moment.

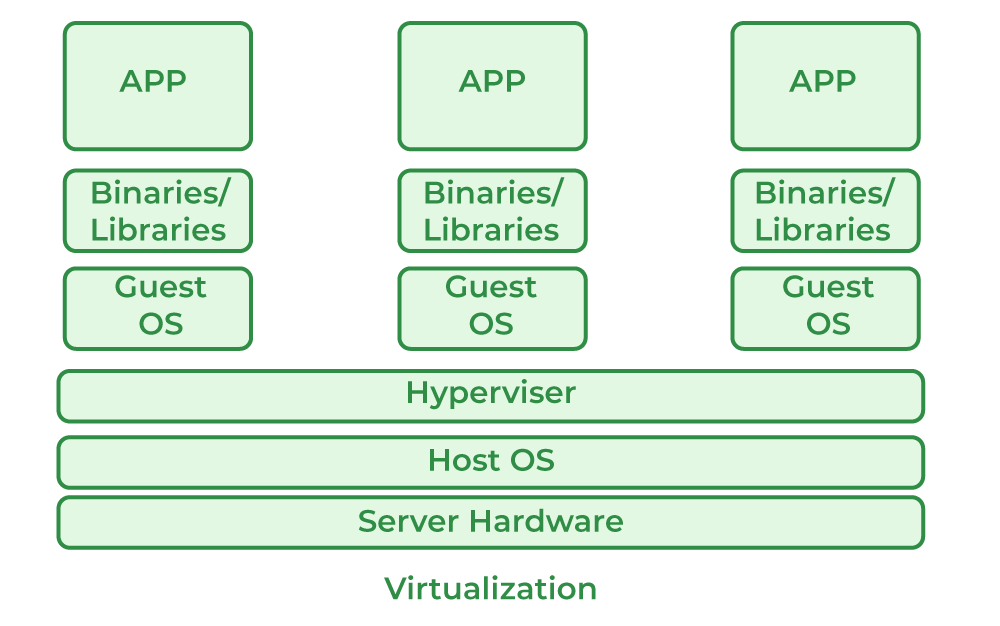
Virtualization allows for computing resources to emulate in software a whole virtual computer at a virtual hardware level.
There are good reasons for this – Namingly for domain separation in that you can run completely different operating systems at the same time on the same physical hardware through a hypervisor and hardware abstractions layers where a disk operation is segmented to lower layers with specific scopes to a given file and back out again to the virtual operating system.
But there is a performance hit in terms of overhead due to virtualization and the “second-system” paravirtualization efforts whereupon functions are translated twice – once within the virtual machine to talk to its virtualized hardware driver to talk to the lower level abstractions of the virtual machine, and again between the virtual machine to the host operating system that actually performs the operation in proxy for the virtual machine.
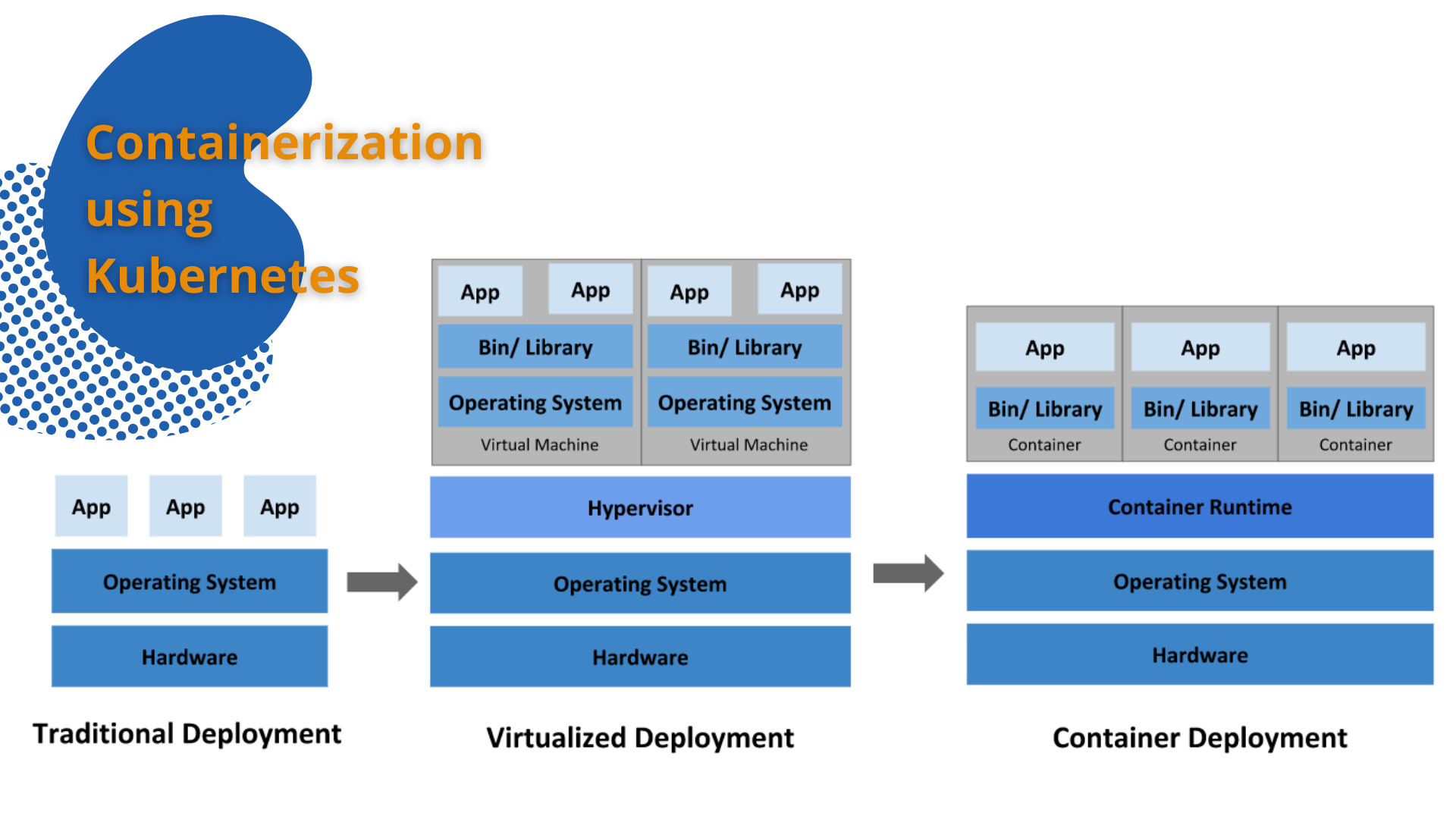
Then comes “containerization” which originally came about as a means of “virtualization” without the hypervisor (a hypervisor being the software layer that does the abstractions between virtual and real hardware).

This came about with the thinking that if you have binaries that can be accessible inside of a “jailed” user-level space, you could technically have an entire other computer system operating on top of the real system that was completely “virtual” in that it could access binaries in a “passthrough” scenario from the host system with the results remaining inside “jailed” space that doesn’t impact the host operations or its configurations.
Docker or containerd are the predominant “containerization” middleware today.
Where I think things have gone fully into “second-system” is Kubernetes which has taken hold in many companies as their panacea to manage numerous containerized “virtual machines”.

Often these containers contain strip down specific versions of libraries and binaries – one of the strengths of containerization is being able to abstract the code from the system operations abstracts – therefore the ability to snapshot a particular configuration.
This is not the problem in my view – it’s the management and utilization of this toolset that becomes a requirement for people to learn as the biggest problem when being on the cutting edge is often plagued with ideas trying to solve what they feel may be immediate or head off what they feel are long term problems – but in the end – lend to increased noise or babel or diaspora of toolsets.
Now, I’m not saying that we should not develop tools that solve problems.
But Docker did create Docker Swarm and Docker-Compose which accomplish everything that Kubernetes tried to arrange – but did it as individual components – not as a overall system.
One must remember that a container is a level of abstraction. And Kubernetes is a container management system often ran inside virtual machines to control containers in a virtual way.
Kubernetes, to me, is a “second-system” anti-pattern.
And it’s already suffering from it.
Helm, the most adopted “configuration” toolset for Kubernetes, has the same issues as older “docker-compose” or “Dockerfile” scripting in that often suffer incompatibilities or deprecated syntaxial issues as the interpreting application evolves which Docker in it’s credit gives better backwards compatibility by versioning the intended “docker-compose.yaml” language version.
Unix and it’s derivatives was built upon, and it’s greatest asset, is that it both:
- Sees everything as a file
- Is an operating system built on tools (binaries/libraries) that utilize other tools (binaries/libraries) all contained within the system that it sees as files.
When we begin to design tools that walk away from the original design aesthetics of the operating system, things tend to go wrong.
